
A lazy adventure in Haskell
 We’re seeing more and more Haskell pop up around Mind Candy. Time to get more familiar with it. Haskell has non-strict semantics, which in practice means a lot of Haskell is lazily evaluated (it’s not the same though).
We’re seeing more and more Haskell pop up around Mind Candy. Time to get more familiar with it. Haskell has non-strict semantics, which in practice means a lot of Haskell is lazily evaluated (it’s not the same though).
For example, look at this piece of Scala code. It squares all the numbers in a list:
val l = List(1,2,3,4) l.map(x => x*x) // --> List(1, 4, 9, 16)
In Haskell this would look something like this:
let l = [1,2,3,4] map (\x -> x*x) l
Only in Haskell, this would generally not do anything! We’re not using the result of the map anywhere. Haskell only evaluates the expression when it needs to. When you want to print it for instance:
let l = [1,2,3,4] putStrLn $ show $ map (\x -> x*x) l // --> [1,4,9,16]
Don’t worry about these ‘$’ signs. It’s basically the same as
putStrLn (show (map (\x -> x*x) l))
It just makes the code less lisp-y. Andshowis more or less just.toString.
Actually, Haskell only evaluates only as much as it needs. So in the following example it would only evaluate the first element, but leave the rest of the list ‘unprocessed’. You could compare this a bit to boolean short-circuit evaluation in languages like Java/C++.
// Omitting the putStrLn but pretend it's there let l = [1,2,3,4] head $ map (\x -> x*x) l // --> 1
 So what good does that do us? In some cases this can actually improve performance. Let’s imagine that you have to get the
So what good does that do us? In some cases this can actually improve performance. Let’s imagine that you have to get the x smallest numbers in a list of n numbers. (Maybe the scores of the winners in a golf tournament? Or the ages of the youngest people in your organisation?) Here’s a Haskell function that takes an x and an n, generates a list of n random numbers, then sorts it, and finally takes the first x numbers.
someFunc :: Int -> Int -> IO () someFunc x n = do -- this is just to show all IO 'as it happens' hSetBuffering stdout NoBuffering numbers <- time "Generating" $ getData n firstX <- time "Sorting" $ take x $ sort numbers putStrLn $ show firstX
We use a sort from the base library. The function getData looks like this:
getData:: Int -> [Int] getData n = take n $ randoms $ mkStdGen n
There’s actually a neat thing in there! The function randoms takes a random number generator and produces an infinite list of random numbers! How come this doesn’t blow up your computer? Well, it produces it lazily, and since we only need the first n, all is well.
The function time just takes an arbitrary computation and prints how long it takes. The code is at the end of this post because it’s not really important right now. In case you’re wondering though, it does force the evaluation of the computation passed to it. Otherwise we would not be able to time it 🙂
These are the results of calling this code with n=2000000 and increasing xs:
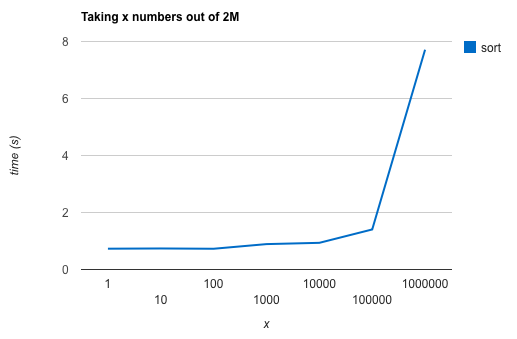
What’s going on!? We’re obviously seeing lazy evaluation in action here. If we only need the first 10 ‘winners’ the sort seems super fast. If we need the first million, i.e., half the list, then sorting becomes much slower. This is simply because we don’t need to sort the whole list just to get the first x results. If we take x=2000000 the code takes ~12 seconds to complete (not shown in graph).
We can force the evaluation of an expression in Haskell by using force or seq (or BangPatterns). Let’s make this small change and try again:
firstX <- time "Sorting" $ take x $ force $ sort numbers
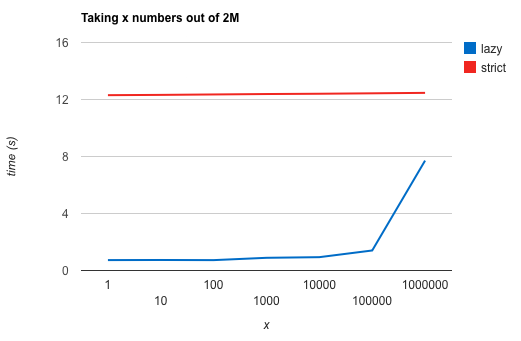
As expected, this code has the same performance for all xs, the full 12 seconds as when we were asking for the completely sorted list.
What now?
The sort algorithm probably has O(n log n) time complexity, which is great. But can we do better, knowing that we only need a small number of values? Here’s an implementation of selection sort.
selSort :: (Ord a) => [a] -> [a]
selSort [] = []
selSort xs = let x = minimum xs in x : selSort (remove x xs)
where remove _ [] = []
remove a (y:ys)
| y == a = ys
| otherwise = y : remove a ys
Selection sort has horrible time complexity O(n^2). This particular implementation can probably be improved and it is not even in-place. Selection sort might be good for our use case though, since it basically builds up the sorted list with the values we want first.
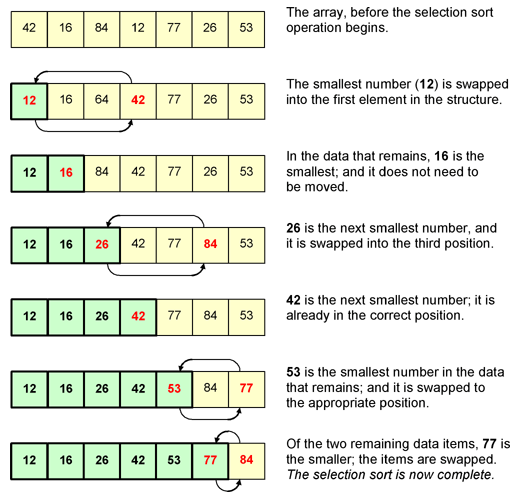
An explanation of selection sort:
© http://www.cs.rmit.edu.au
Here are the results alongside the results for the standard sort, for the first 100 xs.
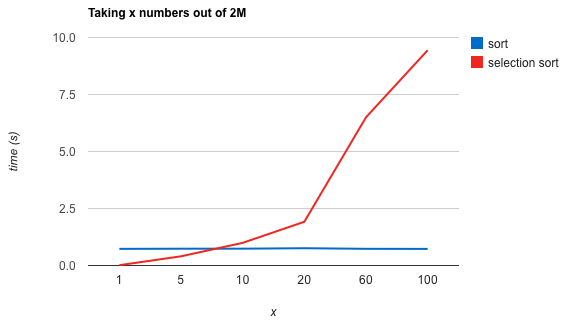
This shows that selection sort beats the standard one for small values of x. Very small values of x…
Conclusion
The lesson is of course that you should still use the optimised sort. Selection sort is faster only if you need just the smallest one in the list, but you might as well use the minimum function! The interesting observation is that due to the laziness, selection sort seems to actually perform as if you’re calling the linear time complexity minimum function! Even though this is an oversimplified example, it is clear that Haskell’s evaluation strategy can have interesting benefits on performance.
Note: micro benchmarks like these are a bit evil. Timings might be different on your own machine and performance of code within a larger program might exhibit very different behaviour.
The code for the time function for completeness sake:
time :: NFData a => String -> a -> IO a
time s a = do
putStr $ s ++ ": "
start <- getCPUTime
let !res = force a
end <- getCPUTime
let diff = (fromIntegral (end - start)) /
(fromIntegral ((10::Integer) ^ (12::Integer)))
printf "%0.3f sec\n" (diff :: Double)
return res
Hi Wouter – do you know of mechanisms in Haskell that enables it to “switch” the implementation automagically based on the value of X. Sort of like a JIT compiler could/would/should?
Hey Oscar, do you mean that it switches between interpreting code and native code?